Microservices architectures offer many benefits, but they also introduce new challenges. One such challenge is the cascading effect of simple failures. A seemingly minor issue in one microservice can quickly snowball, impacting other services and ultimately disrupting user experience.
The Domino Effect: From Certificate Expiry to User Frustration
Imagine a scenario where a microservice’s certificate expires. This seemingly trivial issue prevents it from communicating with others. This disruption creates a ripple effect:
- Microservice Certificate Expiry: The seemingly minor issue is a certificate going past its expiration date.
- Communication Breakdown: This expired certificate throws a wrench into the works, preventing the microservice from securely communicating with other dependent services. It’s like the microservice is suddenly speaking a different language that the others can’t understand.
- Dependent Service Unavailability: Since the communication fails, dependent services can no longer access the data or functionality provided by the failing microservice. Imagine a domino not receiving the push because the first one didn’t fall.
- Errors and Outages: This lack of access leads to errors within dependent services. They might malfunction or crash entirely, causing outages – the domino effect starts picking up speed.
- User Frustration (500 Errors): Ultimately, these outages translate to error messages for the end users. They might see cryptic “500 errors” or experience the dreaded “service unavailable” message – the domino effect reaches the end user, who experiences the frustration.
The Challenge: Untangling the Web of Issues
Cascading failures pose a significant challenge due to the following reasons:
- Network Effect: The root cause gets obscured by the chain reaction of failures, making it difficult to pinpoint the source.
- Escalation Frenzy: Customer complaints trigger incident tickets, leading to a flurry of investigations across multiple teams (DevOps Teams, Service Desk, customer support, etc.).
- Resource Drain: Troubleshooting consumes valuable time from developers, SREs, and support personnel, diverting them from core tasks.
- Hidden Costs: The financial impact of lost productivity and customer dissatisfaction often goes unquantified.
Beyond Certificate Expiry: The Blast Radius of Microservice Issues
Certificate expiry is just one example. Other issues with similar cascading effects include:
- Noisy Neighbors: A resource-intensive microservice can degrade performance for others sharing the same resources (databases, applications) which in turn impact other services that depend on them.
- Code Bugs: Code errors within a microservice can lead to unexpected behavior and downstream impacts.
- Communication Bottlenecks: Congestion or malfunctioning in inter-service communication channels disrupts data flow and service availability.
- Third-Party Woes: Outages or performance issues in third-party SaaS services integrated with your microservices can create a ripple effect.
Platform Pain Points: When Infrastructure Falters
The impact can extend beyond individual microservices. Platform-level issues can also trigger cascading effects:
- Load Balancer Misconfigurations: Incorrectly configured load balancers can disrupt service delivery to clients and dependent services.
- Container Cluster Chaos: Problems within Kubernetes pods, nodes, can lead to application failures and service disruptions.
Blast Radius and Asynchronous Communication: The Data Lag Challenge
Synchronous communication provides immediate feedback, allowing the sender to know if the message was received successfully. In contrast, asynchronous communication introduces a layer of complexity:
- Unpredictable Delivery: Messages may experience varying delays or, in extreme cases, be lost entirely. This lack of real-time confirmation makes it difficult to track the message flow and pinpoint the exact location of a breakdown.
- Limited Visibility: Unlike synchronous communication where a response is readily available, troubleshooting asynchronous issues requires additional effort. You may only have user complaints as a starting point, which can be a delayed and incomplete indicator of the problem.
The root cause of problems could be because of several factors that result delays or lost messages in asynchronous communication:
Microservice Issues:
- Congestion: A microservice overloaded with tasks may struggle to process or send messages promptly, leading to delays.
- Failures: A malfunctioning microservice may be entirely unable to process or send messages, disrupting the flow of data.
Messaging Layer Issues:
Problems within the messaging layer itself can also cause disruptions:
- Congestion: Congestion in message brokers, clusters, or cache instances can lead to delays in message delivery.
- Malfunctions: Malfunctions within the messaging layer can cause messages to be lost entirely.
The Cause & Effect Engine: Unveiling the Root of Microservice Disruptions in Real Time
So what can we do to tame this chaos?
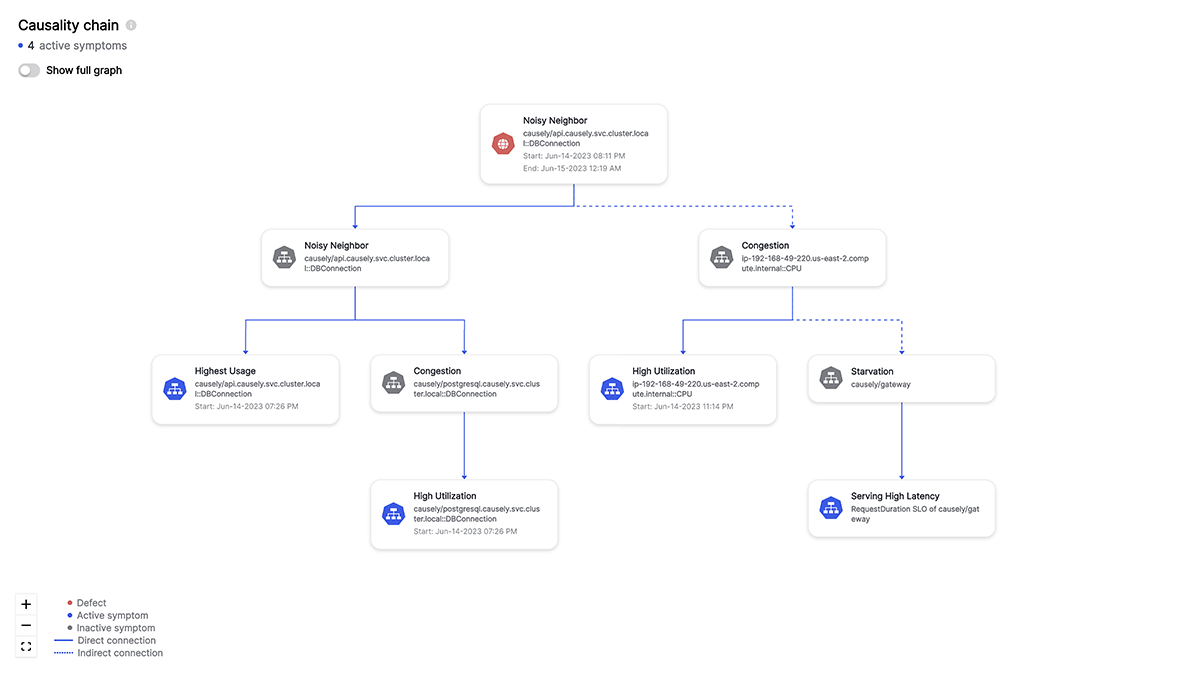
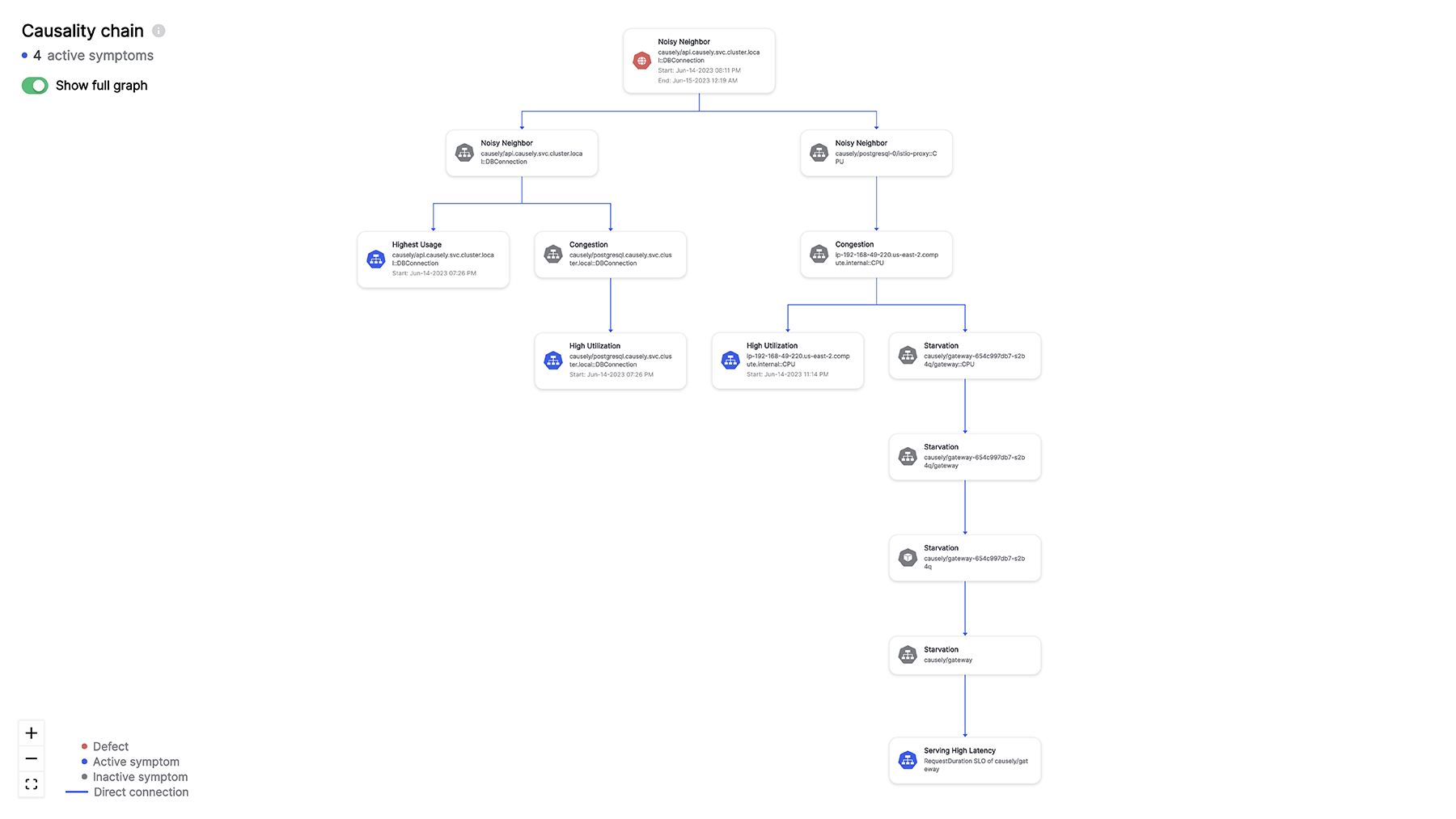
Imagine a system that acts like a detective for your application services. It understands all of the cause-and-effect relationships within your complex architecture. It does this by automatically discovering and analyzing your environment to maintain an up-to-date picture of services, infrastructure and dependencies and from this computes a dynamic knowledge base of root causes and the effects they will have.
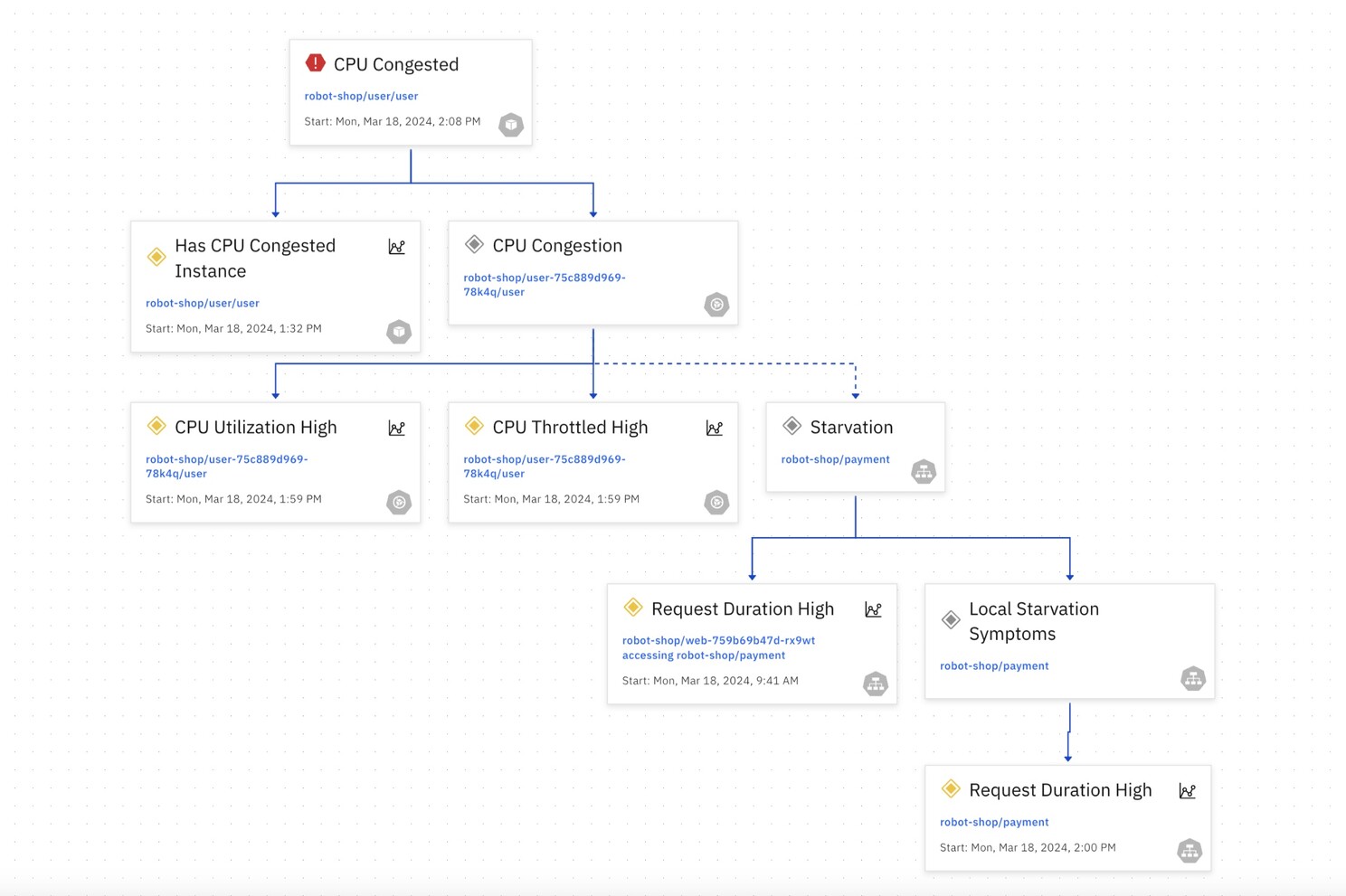
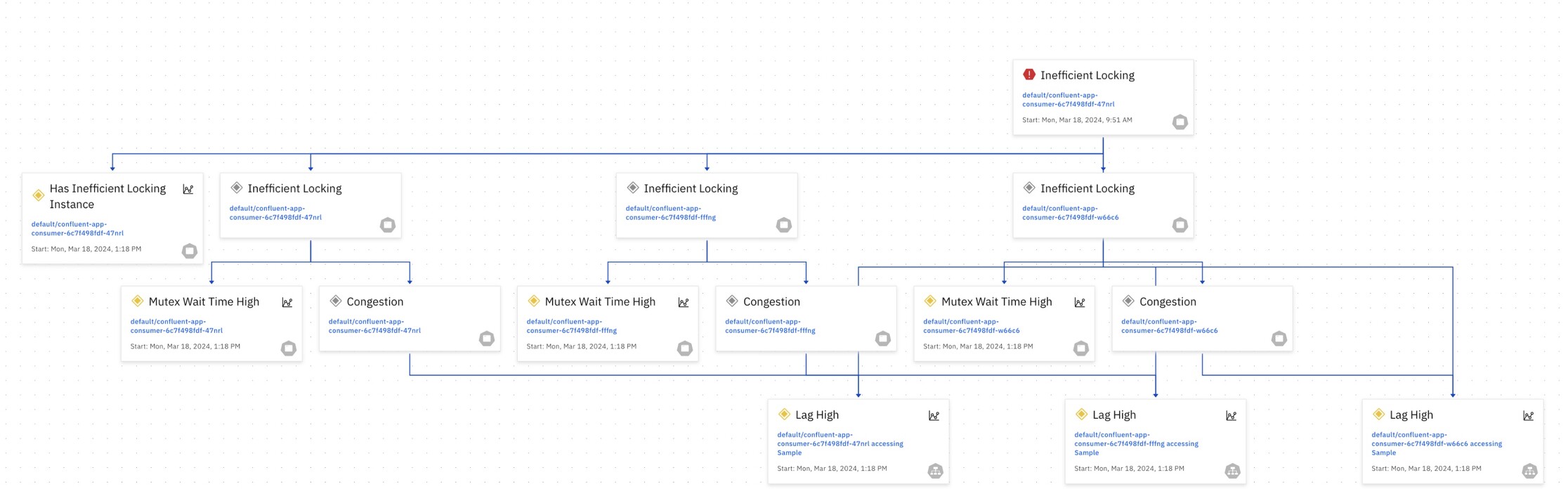
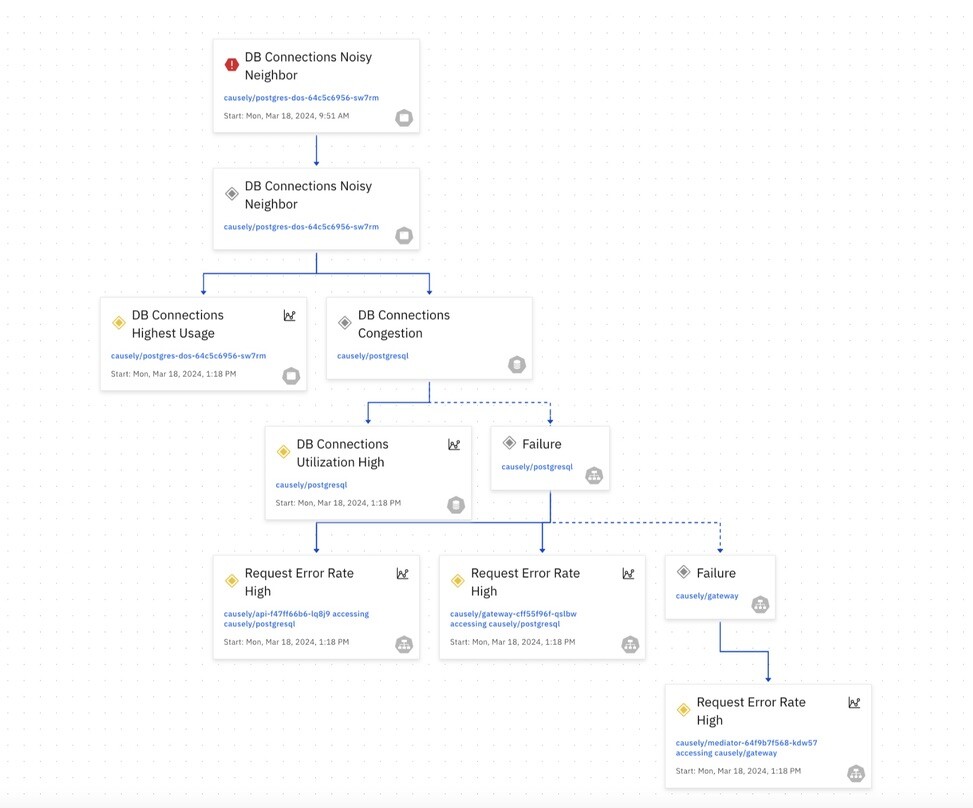
This knowledge is automatically computed in a Causality Graph that depicts all of the relationships between the potential root causes that could occur and the symptoms they may cause. In an environment with thousands of entities, it might represent hundreds of thousands of problems and the set of symptoms each one will cause.
A separate data structure is derived from this called a “Codebook“. This table is like a giant symptom checker, mapping all the potential root causes (problems) to the symptoms (errors) they might trigger.

Hence, each root cause in the Codebook has a unique signature, a vector of m probabilities, that uniquely identifies the root cause. Using the Codebook, the system quickly searches and pinpoints the root causes based on the observed symptoms.
The Causality Graph and Codebook are constantly updated as application services and infrastructure evolve. This ensures the knowledge in the Causality Graph and Codebook stays relevant and adapts to changes.
These powerful capabilities enable:
- Machine Speed Root Cause Identification: Unlike traditional troubleshooting, the engine can pinpoint the culprit in real time, saving valuable time and resources.
- Prioritization Based on Business Impact: By revealing the effects of specific root causes on related services, problem resolution can be prioritized.
- Reduced Costs: Faster resolution minimizes downtime and associated costs.
- Improved Collaboration: Teams responsible for failing services receive immediate notifications and a visualize a Causality Graph explaining the issue’s origin and impact. This streamlines communication and prioritizes remediation efforts based on the effect the root cause problem has.
- Automated Actions: In specific cases, the engine can even trigger automated fixes based on the root cause type.
- Empowered Teams: Teams affected by the problem are notified but relieved of troubleshooting burdens. They can focus on workarounds or mitigating downstream effects, enhancing overall system resilience.
The system represents a significant leap forward in managing cloud native applications. By facilitating real-time root cause analysis and intelligent automation, it empowers teams to proactively address disruptions and ensure the smooth operation of their applications.
The knowledge in the system is not just relevant to optimize the incident response process. It is also valuable for performing “what if” analysis to understand what the impact of future changes and planned maintenance will have so that steps can be taken to proactively understand and mitigate the risks of these activities.
Through its understanding of cause and effect, it can also play a role in business continuity planning, enabling teams to identify single points of failure in complex services to improve service resilience.
The system can also be used to streamline the process of incident postmortems because it contains the prior history of previous root cause problems, why they occurred and what the effect was — their causality. This avoids the complexity and time involved in reconstructing what happened and enables mitigating steps to be taken to avoid recurrences.
The Types of Root Cause Problems & Their Effects
The system computes its causal knowledge based on Causal Models. These describe the behaviours of how root cause problems will propagate symptoms along relationships to dependent entities independently of a given environment. This knowledge is instantiated through service and infrastructure auto discovery to create the Causal Graph and Codebook.

Examples of these types of root cause problems that are modeled in the system include:




Science Fiction or Reality
The inventions behind the system go back to the 90’s, and was at the time and still is groundbreaking. It was successfully deployed, at scale, by some of the largest telcos, system integrators and Fortune 500 companies in the early 2000’s. You can read about the original inventions here.
Today the problems that these inventions set out to address have not changed and the adoption of cloud-native technologies has only heightened the need for a solution. As real-time data has become pervasive in today’s application architectures, every second of service disruption is a lost business opportunity.
These inventions have been taken and engineered in a modern, commercially available platform by Causely to address the challenges of assuring continuous application reliability in the cloud-native world. The founding engineering team at Causely were the creators of the tech behind two high-growth companies: SMARTS and Turbonomic.
If you would like to learn more about this, don’t hesitate to reach out to me directly or comment here.