Application reliability is a dynamic challenge, especially in cloud-native environments. Ensuring that your applications are running smoothly is make-or-break when it comes to user experience. One essential tool for this is the Kubernetes readiness probe. This blog will explore the concept of a readiness probe, explaining how it works and why it’s a key component for managing your Kubernetes clusters.

What is a Kubernetes Readiness Probe?
A readiness probe is essentially a check that Kubernetes performs on a container to ensure that it is ready to serve traffic. This check is needed to prevent traffic from being directed to containers that aren’t fully operational or are still in the process of starting up.
By using readiness probes, Kubernetes can manage the flow of traffic to only those containers that are fully prepared to handle requests, thereby improving the overall stability and performance of the application.
Readiness probes also help in preventing unnecessary disruptions and downtime by only including healthy containers in the load balancing process. This is an essential part of a comprehensive SRE operational practice for maintaining the health and efficiency of your Kubernetes clusters.
How Readiness Probes Work
Readiness probes are configured in the pod specification and can be of three types:
- HTTP Probes: These probes send an HTTP request to a specified endpoint. If the response is successful, the container is considered ready.
- TCP Probes: These probes attempt to open a TCP connection to a specified port. If the connection is successful, the container is considered ready.
- Command Probes: These probes execute a command inside the container. If the command returns a zero exit status, the container is considered ready.
Below is an example demonstrating how to configure a readiness probe in a Kubernetes deployment:
apiVersion: v1
kind: Pod
metadata:
name: readiness-example
spec:
containers:
- name: readiness-container
image: your-image
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
This YAML file defines the Kubernetes pod with a readiness probe configured based on the following parameters:
- apiVersion: v1 – Specifies the API version used for the configuration.
- kind: Pod – Indicates that this configuration is for a Pod.
- metadata:
- name: readiness-example – Sets the name of the Pod to “readiness-example.”
- spec – Describes the desired state of the Pod.
- containers:
- name: readiness-container – Names the container within the Pod as “readiness-container.”
- image: your-image – Specifies the container image to use, named “your-image.”
- readinessProbe – Configures a readiness probe to check if the container is ready to receive traffic.
- httpGet:
- path: /healthz – Sends an HTTP GET request to the /healthz path.
- port: 8080 – Targets port 8080 for the HTTP GET request.
- initialDelaySeconds: 5 – Waits 5 seconds before performing the first probe after the container starts.
- periodSeconds: 10 – Repeats the probe every 10 seconds.
- httpGet:
- containers:
This relatively simple configuration creates a Pod named “readiness-example” with a single container running “your-image.” It includes a readiness probe that checks the /healthz endpoint on port 8080, starting 5 seconds after the container launches and repeating every 10 seconds to determine if the container is ready to accept traffic.
Importance of Readiness Probes
The goal is to make sure you can prevent traffic from being directed to a container that is still starting up or experiencing issues. This helps maintain the overall stability and reliability of your application by only sending traffic to containers that are ready to handle it.
Readiness probes can be used in conjunction with liveness probes to further enhance the health checking capabilities of your containers.
Readiness probes are important for a few reasons:
- Prevent traffic to unready pods: They ensure that only ready pods receive traffic, preventing downtime and errors.
- Facilitate smooth rolling updates: By making sure new pods are ready before sending traffic to them.
- Enhanced application stability: They can help with the overall stability and reliability of your application by managing traffic flow based on pod readiness.
Remember that your readiness probes only check for availability, and don’t understand why a container is not available. Readiness probe failure is a symptom that can manifest from many root causes. It’s important to know the purpose, and limitations before you rely too heavily on them for overall application health.
Related: Causely solves the root cause analysis problem, applying Causal AI to DevOps. Learn about our Causal Reasoning Platform.
Best Practices for Configuring Readiness Probes
To make the most of Kubernetes readiness probes, consider the following practices:
- Define Clear Health Endpoints: Ensure your application exposes a clear and reliable health endpoint.
- Set Appropriate Timing: Configure initialDelaySeconds and periodSeconds based on your application’s startup and response time.
- Monitor and Adjust: Continuously monitor the performance and adjust the probe configurations as needed.
For example, if your application requires a database connection to be fully established before it can serve requests, you can set up a readiness probe that checks for the availability of the database connection.
By configuring the initialDelaySeconds and periodSeconds appropriately, you can ensure that your application is only considered ready once the database connection is fully established. This will help prevent any potential issues or errors that may occur if the application is not fully prepared to handle incoming requests.
Limitations of Readiness Probes
Readiness probes are handy, but they only check for the availability of a specific resource and do not take into account the overall health of the application. This means that even if the database connection is established, there could still be other issues within the application that may prevent it from properly serving requests.
Additionally, readiness probes do not automatically restart the application if it fails the check, so it is important to monitor the results and take appropriate action if necessary. Readiness probes are still a valuable tool for ensuring the stability and reliability of your application in a Kubernetes environment, even with these limitations.
Troubleshooting Kubernetes Readiness Probes: Common Issues and Solutions
Slow Container Start-up
Problem: If your container’s initialization tasks exceed the initialDelaySeconds of the readiness probe, the probe may fail.
Solution: Increase the initialDelaySeconds to give the container enough time to start and complete its initialization. Additionally, optimize the startup process of your container to reduce the time required to become ready.
Unready Services or Endpoints
Problem: If your container relies on external services or dependencies (e.g., a database) that aren’t ready when the readiness probe runs, it can fail. Race conditions may also occur if your application’s initialization depends on external factors.
Solution: Ensure that external services or dependencies are ready before the container starts. Use tools like Helm Hooks or init containers to coordinate the readiness of these components with your application. Implement synchronization mechanisms in your application to handle race conditions, such as using locks, retry mechanisms, or coordination with external components.
Misconfiguration of the Readiness Probe
Problem: Misconfigured readiness probes, such as incorrect paths or ports, can cause probe failures.
Solution: Double-check the readiness probe configuration in your Pod’s YAML file. Ensure the path, port, and other parameters are correctly specified.
Application Errors or Bugs
Problem: Application bugs or issues, such as unhandled exceptions, misconfigurations, or problems with external dependencies, can prevent it from becoming ready, leading to probe failures.
Solution: Debug and resolve application issues. Review application logs and error messages to identify the problems preventing the application from becoming ready. Fix any bugs or misconfigurations in your application code or deployment.
Insufficient Resources
Problem: If your container is running with resource constraints (CPU or memory limits), it might not have the resources it needs to become ready, especially under heavy loads.
Solution: Adjust the resource limits to provide the container with the necessary resources. You may also need to optimize your application to use resources more efficiently.
Conflicts Between Probes
Problem: Misconfigured liveness and readiness probes might interfere with each other, causing unexpected behavior.
Solution: Ensure that your probes are configured correctly and serve their intended purposes. Make sure that the settings of both probes do not conflict with each other.
Cluster-Level Problems
Problem: Kubernetes cluster issues, such as kubelet or networking problems, can result in probe failures.
Solution: Monitor your cluster for any issues or anomalies and address them according to Kubernetes best practices. Ensure that the kubelet and other components are running smoothly.
These are common issues to keep an eye out for. Watch for problems that the readiness probes are not surfacing or that might be preventing them from acting as expected.
Summary
Ensuring that your applications are healthy and ready to serve traffic is necessary for maximizing uptime. The Kubernetes readiness probe is one helpful tool for managing Kubernetes clusters; it should be a part of a comprehensive Kubernetes operations plan.
Readiness probes can be configured in pod specifications and can be HTTP, TCP, or command probes. They help prevent disruptions and downtime by ensuring only healthy containers are included in the load-balancing process.
They also use the prevention of sending traffic to unready pods for smooth rolling updates and enhancing application stability. It’s good practice that your readiness probes include defining clear health endpoints, setting appropriate timing, and monitoring and adjusting configurations.
Don’t forget that readiness probes have clear limitations, as they only check for the availability of a specific resource and do not automatically restart the application if it fails the check. A Kubernetes readiness probe failure is merely a symptom that can be attributed to many root causes. To automate root cause analysis across your entire Kubernetes environment, check out Causely for Cloud-Native Applications.
Related resources
- Webinar: What is Causal AI and why do DevOps teams need it?
- Blog: Bridging the gap between observability and automation with causal reasoning
- Product Overview: Causely for Cloud-Native Applications



























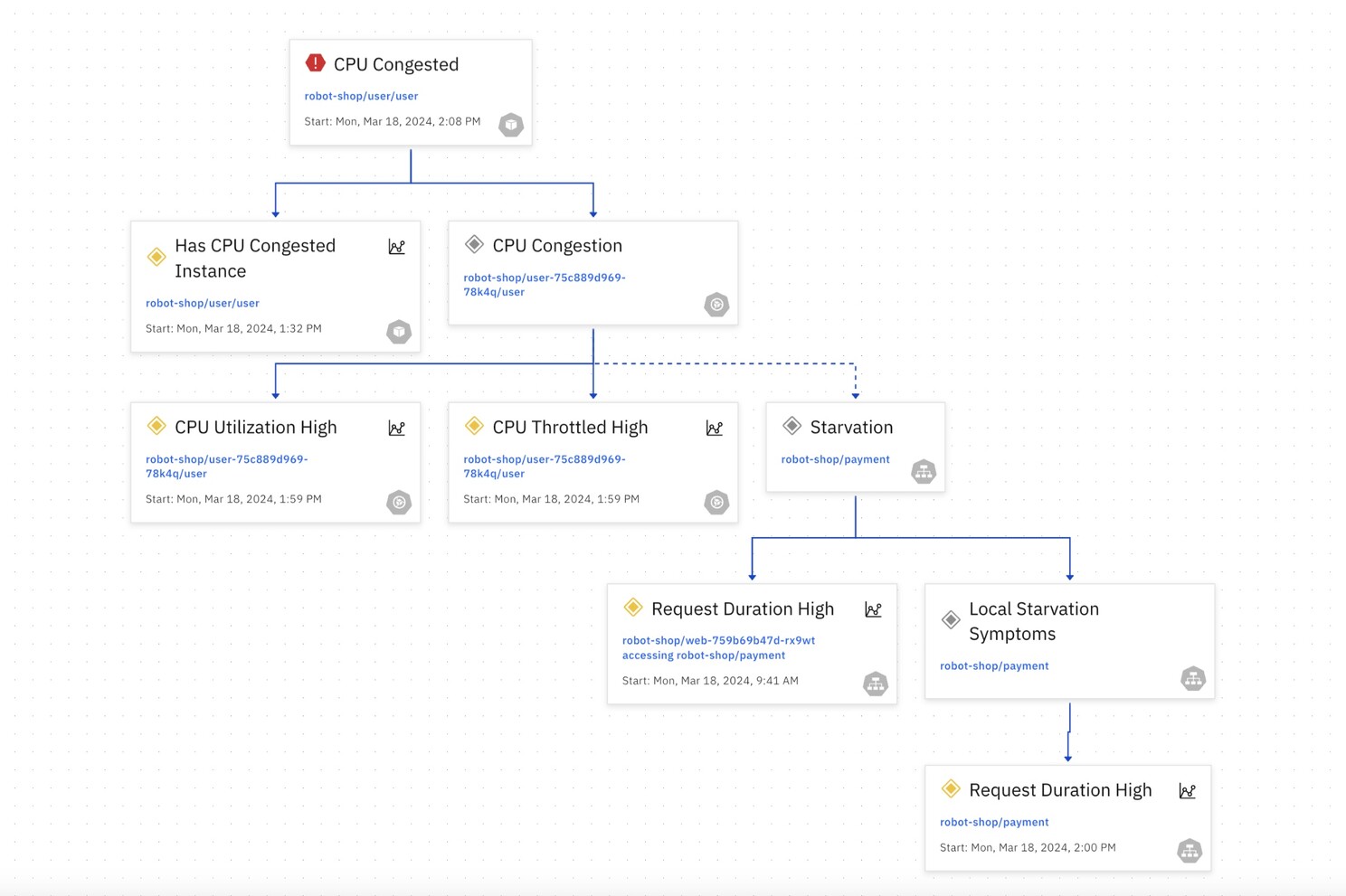
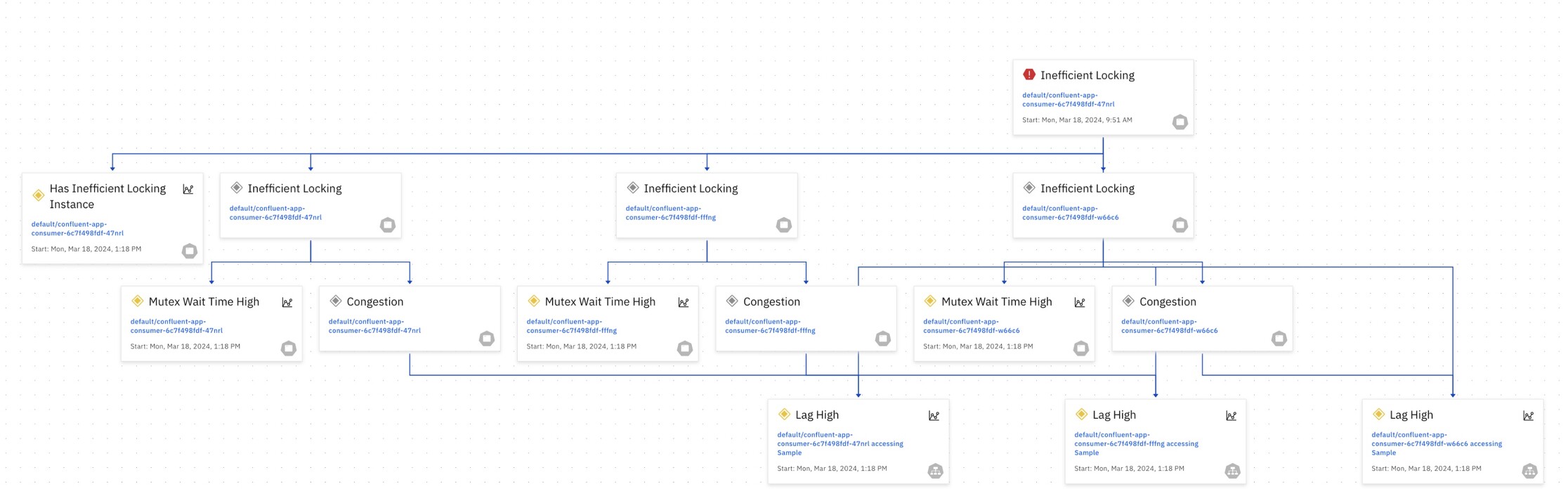
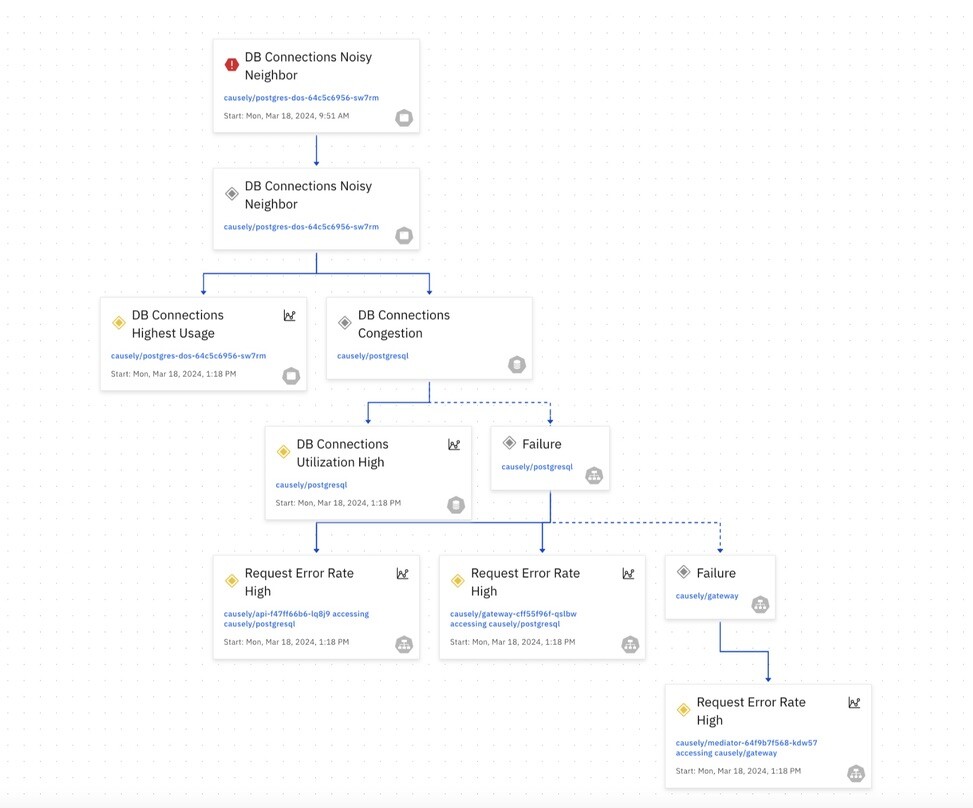




 In the fast-paced world of cloud-native development, ensuring application health and performance is critical. The application of
In the fast-paced world of cloud-native development, ensuring application health and performance is critical. The application of 













 The fate of the realm hangs in the balance. Join the mayhem in Cloud Cuckoo Calamity, the thrilling sequel to
The fate of the realm hangs in the balance. Join the mayhem in Cloud Cuckoo Calamity, the thrilling sequel to